Register to participate in this challenge on the MediaEval 2016 registration site.
TV archives maintained by national institutions such as the French INA, the Netherlands Institute for Sound & Vision, or the BBC are rapidly growing in size. The need for applications that make these archives searchable has led researchers to devote concerted effort to developing technologies that create indexes.
Indexes that represent identity of people in the archive are indispensable for searching archives. Human nature leads people to be very interested in other people. However, at the moment that content is created or broadcasted, it is not always possible to predict which people will be the most important to find in the future. Someone who appeared in a broadcast, but was relatively unnoticed, might suddenly start generating a buzz and become a trending topic on social networks or search engines. For this reason, it is not possible to assume that a biometric model capable of detecting an individual, will be present at indexing time. For some people such a model may not be available in advance, simply because they are not (yet) famous. In such cases, it is also possible that archivists annotating content by hand do not even know the name of the person. The goal of this task is to address the challenge of indexing people in the archive, under real-world conditions (i.e., there is no pre-set list of people to index).
Participants are provided with a collection of TV broadcasts pre-segmented into shots, along with the output of several baseline components such as speaker diarization, face detection and tracking, speech transcription, video OCR and named entity detection.
Participants are asked to provide, for each shot, the list of names of persons speaking AND appearing at the same time. The main challenge of this task is that the list of persons is not provided a priori, and person models (neither voice nor face) may not be trained on external data. The only way to identify a person is by finding their name in the audio (e.g., using speech transcription) or visual (e.g., using optical character recognition) streams and associating them to the correct person making the task completely unsupervised.
For each returned shot, participants are also asked to provide the evidence justifying their assertion (e.g. a short excerpt of the test set showing the person AND its name at the same time).
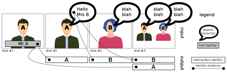
In this second edition of Person Discovery, secondary runs may additionally make use of attached textual metadata available alongside the corpus (e.g. subtitles, electronic program guide, textual description, etc...). Primary runs, however, cannot make use of this extra source of information.
Target group
This task targets researchers from several communities including multimedia, computer vision, speech and natural language processing. Though the task is multimodal by design and necessitates expertise in various domains, the technological barriers to entry is lowered by the fact that the automatic output of various sub-modules will be provided to all participants (speaker diarization, face detection and tracking, automatic speech transcription, optical character recognition, named entity detection and an automatic speaker and face naming system as baseline).
For instance, a researcher from the speech processing community could focus its research efforts on improving speaker diarization and automatic speech transcription, while still being able to rely on provided face detection and tracking results to participate to the task.
Data
"6 Months of Broadcast News" corpus from INA (Person Discovery 2015 test set) will serve as training set in 2016. Reference labels generated last year during the collaborative annotation campaign will be shared with participants.
Following last year's participant remarks, we are currently in the process of gathering a more diverse test set, including several types of show and several languages. This year development and test sets will include:
• a subset of a new INA corpus made of a full week of three French TV channels (24/7 recordings)
• a subset of the DW/EUMSSI corpus
• a subset of the Catalan TV-3 24 corpus
All these corpora will be distributed with textual metadata and output of various automatic modules (e.g. speaker diarization, face detection and tracking, automatic speech transcription, optical character recognition, named entity detection).
Ground truth and evaluation
Participants are asked to return the names (and corresponding confidence scores and evidence) of people speaking AND appearing at the same time, for each shot of the video.
Based on participant submissions, a set of “firstname_lastname” queries will be gathered. Shots tagged with the closest name to the query (according to string edit distance) will be selected, ranked according to their confidence score, and evaluated using standard Mean Average Precision. Note that both queries and names will be normalized beforehand (by removing diacritical and all but the 26 case-insensitive Latin alphabet characters and space).
Groundtruth for both the development and the evaluation sets will be created by participants themselves through the dedicated collaborative annotation web interface successfully used for the first edition of Person Discovery 2016 [3]. The submission website will open for the whole duration of the task, alongside a live leaderboard providing feedback on the actual performance of current submissions on the development set. The more annotations are generated by participants, the more reliable the performance estimation will be.
Recommended reading
[1] Poignant, J., Bredin, H., Barras, C. Multimodal Person Discovery in Broadcast TV at MediaEval 2015. Working Notes Proceedings of the MediaEval 2015 Workshop. Wurzen, Germany, 2015.
[2] Poignant, J., Bredin, H., Barras C. Multimodal Person Discovery in Broadcast TV: lessons learned from MediaEval 2015. Submitted to IEEE Transactions on Multimedia, 2016.
[3] Poignant, J., Bredin, H., Barras C., Stefas, M., Bruneau, P., Tamisier, T. Benchmarking multimedia technologies with the CAMOMILE platform: the case of Multimodal Person Discovery at MediaEval 2015. In Proceedings of the 10th LREC Language Resources and Evaluation Conference. Portoroz, Slovenia, 2016.
Task organizers
Hervé Bredin, LIMSI, CNRS, France
Camille Guinaudeau, LIMSI, Université Paris-Sud, France
Claude Barras, LIMSI, Université Paris-Sud, France
Task schedule
1 June 2016: Development & test data release
13 September 2016: Run submission
30 September 2016: Working notes paper deadline
20-21 October 2016: MediaEval 2016 Workshop, Right after ACM MM 2016 in Amsterdam.
Acknowledgments
The French National Research Agency

