Check out the CAMOMILE collaborative annotation framework used by this task. The source code is available under an MIT Open Source license: http://camomile.limsi.fr
TV archives maintained by national institutions such as the French INA, the Netherlands Institute for Sound & Vision, or the BBC are rapidly growing in size. The need for applications that make these archives searchable has led researchers to devote concerted effort to developing technologies that create indexes.
Indexes that represent the location and identity of people in the archive are indispensable for searching archives. Human nature leads people to be very interested in other people. However, at the moment that content is created or broadcast, it is not always possible to predict which people will be the most important to find in the future. Someone who appeared in a broadcast, but was relatively unnoticed, might suddenly start generating a buzz and become a trending topic on social networks or search engines. For this reason, it is not possible to assume that a biometric models capable of detecting an individual, will be present at indexing time. For some people such a model may not be available in advance, simply because they are not (yet) famous. In such cases, it is also possible that archivists annotating content by hand do not even know the name of the person. The goal of this task is to address the challenge of indexing people in the archive, under real-world conditions (i.e., there is no pre-set list of people to index).
This task represents an extension of the (now completed) French REPERE challenge, which focused on multimodal person recognition in TV broadcast. The main objective of this challenge was to answer the two questions "Who speaks when?" and "Who appears when?" using any sources of information (including pre-existing biometric models and person names extracted from text overlay and speech transcripts). In this new task, only unsupervised algorithms (i.e., algorithms not relying on pre-existing labels or biometric models) are admitted. To ensure high quality indexes, those algorithms should also help human annotators double-check these indexes by providing an evidence of the claimed identity (especially for people who are not yet famous).
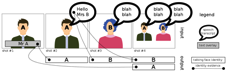
Given raw TV broadcasts, each shot must be automatically tagged with the name(s) of people who can be both seen as well as heard in the shot. The list of people is not known a priori and their names must be discovered in an unsupervised way from provided text overlay or speech transcripts.
Participants are provided with a collection of TV broadcasts pre-segmented into shots, along with the output of several baseline components: speaker diarization, face detection and tracking, speech transcription, video OCR and named entity detection.
Participants are asked to provide, for each shot, the list of names of persons speaking AND appearing at the same time. The main novelty of the task is that the list of persons is not provided a priori, and person models (neither voice nor face) may not be trained on external data. The only way to identify a person is by finding their name in the audio (e.g., using speech transcription) or visual (e.g., using optical character recognition) streams and associating them to the correct person making the task completely unsupervised. For each returned shot, participants are also asked to provide the evidence justifying their assertion (e.g. a short excerpt of the test set showing the person AND its name at the same time).
Target group
This task targets researchers from several communities including multimedia, computer vision, speech and natural language processing. Though the task is multimodal by design and necessitates expertise in various domains, the technological barriers to entry is lowered by the fact that the automatic output of various sub-modules will be provided to all participants (speaker diarization, face detection and tracking, automatic speech transcription, optical character recognition, named entity detection and an automatic speaker and face naming system as baseline).
For instance, a researcher from the speech processing community could focus its research efforts on improving speaker diarization and automatic speech transcription, while still being able to rely on provided face detection and tracking results to participate to the task.
Data
The original REPERE corpus set will be used as development set. This corpus is composed of various TV shows (focusing on news, politics and people) from two French TV channels. It will be distributed by ELDA (Evaluation and Language resources Distribution Agency) freely or at distribution cost. Among those 137 hours, 50 are already manually annotated. Audio annotations are dense and provide speech transcripts and identity-labeled speech turns. Video annotations are sparse (one image every 10 seconds) and provide overlaid text transcripts and identity-labeled face segmentation. Both speech and overlaid text transcripts are tagged with named entities.
The test set is composed of two corpora, a French TV news corpus provided by INA and the Catalan AGORA corpus. The INA corpus contains 115 hours of video, corresponding to 181 editions of evening broadcast news "Le 20 heures" of French public channel "France 2", from January 1st 2007 to June 30st 2007. Videos are provided as 181 MPEG1 files.
The AGORA dataset contains 43 hours of various TV shows (debates with a high variation in topics and invited speakers) from the Catalan public channel TV3.
Ground truth and evaluation
Participants are asked to return the names (and corresponding confidence scores and evidence) of people speaking and appearing at the same time, for each shot of the video. Those results will not be evaluated directly: they will serve as the index for a simple search experiment which, in turn, will be evaluated through mean average precision.
Here is how the search experiment is designed. Based on participant submissions, we will select a set of queries following the form: “PersonFirstName PersonLastName” possibly restricted to a temporal interval. For each query and for each video within the chosen period, the shots for which a submitted person name is close to the query name (i.e. by applying a predefined threshold on a string distance) will be selected and ranked according to their confidence score. Note that both queries and names will be normalized beforehand (by removing diacritical and all but the 26 case-insensitive Latin alphabet characters and space). This procedure results in an Average Precision specific to the query and to the video. In order to prevent giving too much weight to predominant people or to individual video, we will first compute the Mean Average Precision over all videos where a particular person is detected, and then compute a Mean Mean Average Precision over all persons.
Average Precision will be modified slightly to take the quality of the evidence into account. Hence, instead of a binary judgment (relevant vs. not relevant), shot relevance will be computed as follows (the value of α will be discussed during the development phase):
{shot relevance} = α . {shot is relevant} + (1 - α) . {evidence is correct}
Groundtruth will be created a posteriori by manually checking the top N shots proposed by participants for each request and the associated evidence. We will kindly ask participants to contribute to the annotation via the collaborative annotation webapp developed in the framework of the CHISTERA Camomile project. Evidences provided by participants will ease and speed up the annotation process. An online adjudication interface will be opened after the first round of evaluations to solve remaining ambiguous cases.
Recommended reading
[1] F. Bechet, M. Bendris, D. Charlet, G. Damnati, B. Favre, M. Rouvier, R. Auguste, B. Bigot, R. Dufour, C. Fredouille, G. Linarès, J. Martinet, G. Senay, P. Tirilly. Multimodal Understanding for Person Recognition in Video Broadcasts. Interspeech 2014, Fifteenth Annual Conference of the International Speech Communication Association, 2014.
[2] H. Bredin, A. Laurent, A. Sarkar, V.-B. Le, S. Rosset, C. Barras. Person Instance Graphs for Named Speaker Identification in TV Broadcast. Odyssey 2014: The Speaker and Language Recognition Workshop, 2014.
[3] G. Bernard, O. Galibert, J. Kahn. The First Official REPERE Evaluation. SLAM 2013, First Workshop on Speech, Language and Audio for Multimedia, 2013.
[4] A. Giraudel, M. Carré, V. Mapelli, J. Kahn, O. Galibert, L. Quintard. The REPERE Corpus: a Multimodal Corpus for Person Recognition. LREC 2014, Eighth International Conference on Language Resources and Evaluation, 2014.
[5] J. Poignant, L. Besacier, G. Quénot. Unsupervised Speaker Identification in TV Broadcast Based on Written Names. IEEE/ACM Transactions on Audio, Speech, and Language Processing, Vol. 23, No. 1, 2015.
Task organizers
Johann Poignant, LIMSI/CNRS, France
Hervé Bredin, LIMSI/CNRS, France
Claude Barras, LIMSI/Université Paris-Sud, France
Task auxiliaries
Félicien Vallet, INA, France
Jean Carrive, INA, France
Valérie Mapelli, ELDA, France
Juliette Kahn, LNE, France
Task schedule
1 May: Development data release
1 June: Test data release
1 July: Run submission
15 July / 15 August: Collaborative annotation
28 August: Working notes paper deadline
14-15 September MediaEval 2015 Workshop
